2026
Code Aesthetics with Agentic Reward Feedback
Bang Xiao*, Lingjie Jiang*, Shaohan Huang#, Tengchao Lv, Yupan Huang, Xun Wu, Lei Cui, Furu Wei (* equal contribution, # corresponding author)
International Conference on Learning Representations (ICLR) 2026
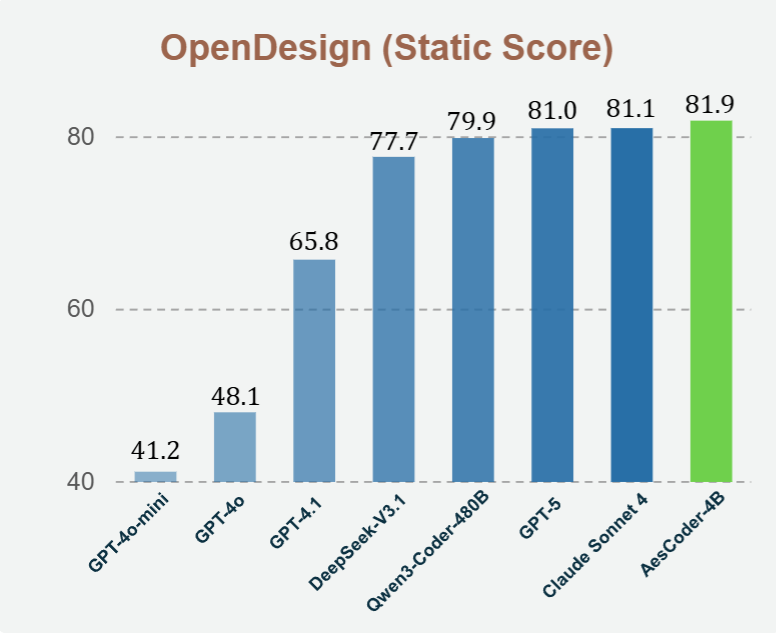
We present a unified framework for aesthetic code generation that substantially improves both visual quality and functionality. With a large-scale dataset, agentic reward feedback, and a new benchmark, our 4B model outperforms GPT-4o and GPT-4.1 and matches the performance of open-source models hundreds of times larger. This work establishes a strong and scalable approach to advancing code aesthetics in large language models.
Code Aesthetics with Agentic Reward Feedback
Bang Xiao*, Lingjie Jiang*, Shaohan Huang#, Tengchao Lv, Yupan Huang, Xun Wu, Lei Cui, Furu Wei (* equal contribution, # corresponding author)
International Conference on Learning Representations (ICLR) 2026
We present a unified framework for aesthetic code generation that substantially improves both visual quality and functionality. With a large-scale dataset, agentic reward feedback, and a new benchmark, our 4B model outperforms GPT-4o and GPT-4.1 and matches the performance of open-source models hundreds of times larger. This work establishes a strong and scalable approach to advancing code aesthetics in large language models.
Efficient and Scalable Monocular Human-Object Interaction Motion Reconstruction
Boran Wen*, Ye Lu*, Keyan Wan, Sirui Wang, Jiahong Zhou, Junxuan Liang, Xinpeng Liu, Bang Xiao, Dingbang Huang, Ruiyang Liu, Yonglu Li# (* equal contribution, # corresponding author)
Under review. 2026
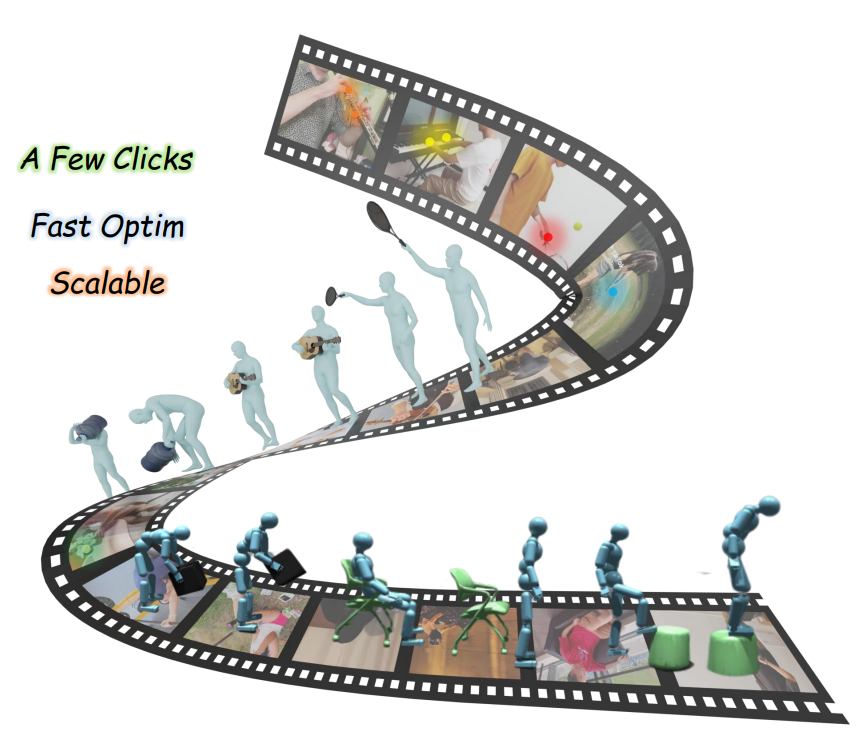
We introduce 4DHOISolver, a human-in-the-loop framework that enables scalable and physically plausible 4D human–object interaction reconstruction from monocular internet videos. Using this approach, we build Open4DHOI, a large-scale dataset with 144 object types and 103 actions, and show that the recovered interactions can drive RL-based imitation learning. Our results also reveal that accurate contact prediction remains a key open challenge for current 3D foundation models.
Efficient and Scalable Monocular Human-Object Interaction Motion Reconstruction
Boran Wen*, Ye Lu*, Keyan Wan, Sirui Wang, Jiahong Zhou, Junxuan Liang, Xinpeng Liu, Bang Xiao, Dingbang Huang, Ruiyang Liu, Yonglu Li# (* equal contribution, # corresponding author)
Under review. 2026
We introduce 4DHOISolver, a human-in-the-loop framework that enables scalable and physically plausible 4D human–object interaction reconstruction from monocular internet videos. Using this approach, we build Open4DHOI, a large-scale dataset with 144 object types and 103 actions, and show that the recovered interactions can drive RL-based imitation learning. Our results also reveal that accurate contact prediction remains a key open challenge for current 3D foundation models.
2024

Token Pruning for Caching Better: 9$\times$ Acceleration on Stable Diffusion for Free
Evelyn Zhang*, Bang Xiao*, Jiayi Tang, Qianli Ma, Chang Zou, Xuefei Ning, Xuming Hu, Linfeng Zhang# (* equal contribution, # corresponding author)
arXiv preprint 2024
Based on token prune and layer cache technology, we present a new Stable Diffusion acceleration method named dynamics-aware token pruning (DaTo). In the COCO-30k, we observed a 7$\times$ acceleration coupled with a notable FID reduction of 2.17.
Token Pruning for Caching Better: 9$\times$ Acceleration on Stable Diffusion for Free
Evelyn Zhang*, Bang Xiao*, Jiayi Tang, Qianli Ma, Chang Zou, Xuefei Ning, Xuming Hu, Linfeng Zhang# (* equal contribution, # corresponding author)
arXiv preprint 2024
Based on token prune and layer cache technology, we present a new Stable Diffusion acceleration method named dynamics-aware token pruning (DaTo). In the COCO-30k, we observed a 7$\times$ acceleration coupled with a notable FID reduction of 2.17.