
Hi👋 I am Bang Xiao, an undergraduate student major in Computer Science at Shanghai Jiao Tong University, supervised by Cewu Lu and Yonglu Li. I am selected as a member of Zhiyuan Honors Program.
Previously, I was a research intern at GenAI Group, Microsoft Research Asia, supervised by Shaohan Huang and Tengchao Lv.
My research interests broadly span generative models, world models, reinforcement learning, and representation learning. My long-term goal is to build intelligent systems that can truly understand the physical world, and are capable of reasoning and planning.
🔍 I am currently looking for Research Assistant opportunities in the USA for 2026. If you are interested, please feel free to contact me!
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 Shanghai Jiao Tong UniversityB.S. in Computer Science, Zhiyuan Honors ProgramSep. 2023 - now
Shanghai Jiao Tong UniversityB.S. in Computer Science, Zhiyuan Honors ProgramSep. 2023 - now -
 No.1 Middle School Affiliated to Central China Normal UniversityHigh SchoolSep. 2020 - Jun. 2023
No.1 Middle School Affiliated to Central China Normal UniversityHigh SchoolSep. 2020 - Jun. 2023
Experience
-
 GenAI Group, Microsoft Research Asia
GenAI Group, Microsoft Research Asia
Superviser: Shaohan Huang and Tengchao LvResearch InternMay. 2025 - Nov. 2025 -
SJTU MVIG Lab
Superviser: Cewu Lu and Yonglu LiResearch InternDec. 2024 - Now -
SJTU EPIC Lab
Superviser: Linfeng ZhangResearch InternAug. 2024 - Dec. 2024
News
Publications (view all )
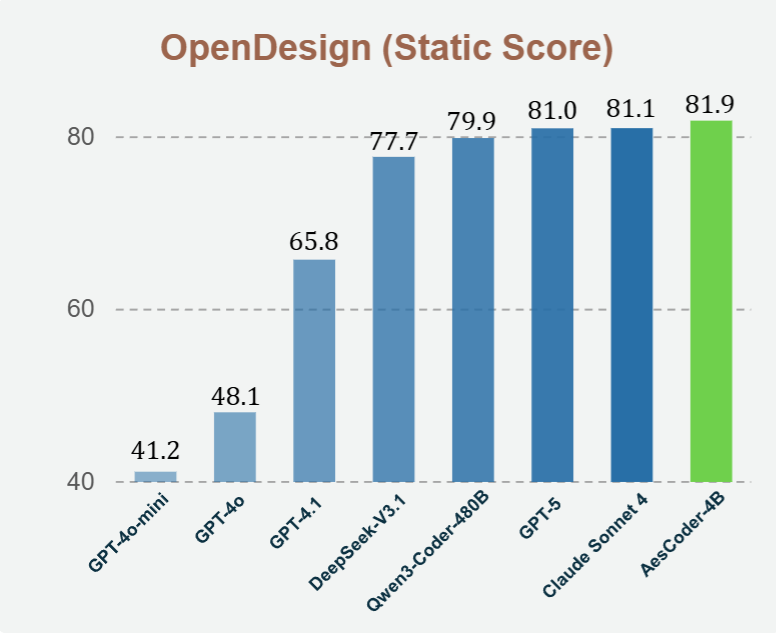
Code Aesthetics with Agentic Reward Feedback
Bang Xiao*, Lingjie Jiang*, Shaohan Huang#, Tengchao Lv, Yupan Huang, Xun Wu, Lei Cui, Furu Wei (* equal contribution, # corresponding author)
International Conference on Learning Representations (ICLR) 2026
We present a unified framework for aesthetic code generation that substantially improves both visual quality and functionality. With a large-scale dataset, agentic reward feedback, and a new benchmark, our 4B model outperforms GPT-4o and GPT-4.1 and matches the performance of open-source models hundreds of times larger. This work establishes a strong and scalable approach to advancing code aesthetics in large language models.
Code Aesthetics with Agentic Reward Feedback
Bang Xiao*, Lingjie Jiang*, Shaohan Huang#, Tengchao Lv, Yupan Huang, Xun Wu, Lei Cui, Furu Wei (* equal contribution, # corresponding author)
International Conference on Learning Representations (ICLR) 2026
We present a unified framework for aesthetic code generation that substantially improves both visual quality and functionality. With a large-scale dataset, agentic reward feedback, and a new benchmark, our 4B model outperforms GPT-4o and GPT-4.1 and matches the performance of open-source models hundreds of times larger. This work establishes a strong and scalable approach to advancing code aesthetics in large language models.
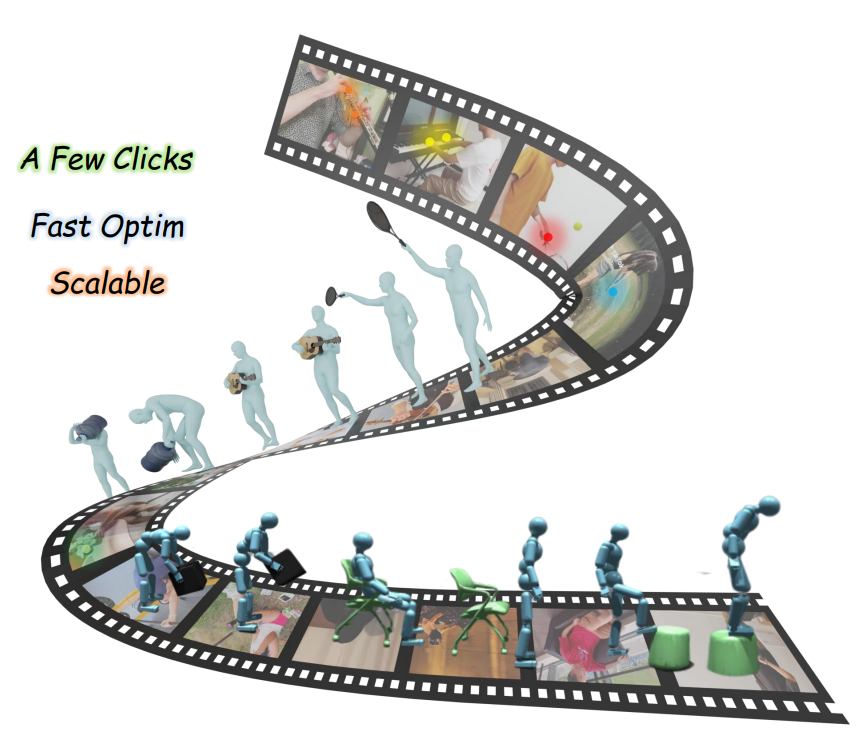
Efficient and Scalable Monocular Human-Object Interaction Motion Reconstruction
Boran Wen*, Ye Lu*, Keyan Wan, Sirui Wang, Jiahong Zhou, Junxuan Liang, Xinpeng Liu, Bang Xiao, Dingbang Huang, Ruiyang Liu, Yonglu Li# (* equal contribution, # corresponding author)
Under review. 2026
We introduce 4DHOISolver, a human-in-the-loop framework that enables scalable and physically plausible 4D human–object interaction reconstruction from monocular internet videos. Using this approach, we build Open4DHOI, a large-scale dataset with 144 object types and 103 actions, and show that the recovered interactions can drive RL-based imitation learning. Our results also reveal that accurate contact prediction remains a key open challenge for current 3D foundation models.
Efficient and Scalable Monocular Human-Object Interaction Motion Reconstruction
Boran Wen*, Ye Lu*, Keyan Wan, Sirui Wang, Jiahong Zhou, Junxuan Liang, Xinpeng Liu, Bang Xiao, Dingbang Huang, Ruiyang Liu, Yonglu Li# (* equal contribution, # corresponding author)
Under review. 2026
We introduce 4DHOISolver, a human-in-the-loop framework that enables scalable and physically plausible 4D human–object interaction reconstruction from monocular internet videos. Using this approach, we build Open4DHOI, a large-scale dataset with 144 object types and 103 actions, and show that the recovered interactions can drive RL-based imitation learning. Our results also reveal that accurate contact prediction remains a key open challenge for current 3D foundation models.

Token Pruning for Caching Better: 9$\times$ Acceleration on Stable Diffusion for Free
Evelyn Zhang*, Bang Xiao*, Jiayi Tang, Qianli Ma, Chang Zou, Xuefei Ning, Xuming Hu, Linfeng Zhang# (* equal contribution, # corresponding author)
arXiv preprint 2024
Based on token prune and layer cache technology, we present a new Stable Diffusion acceleration method named dynamics-aware token pruning (DaTo). In the COCO-30k, we observed a 7$\times$ acceleration coupled with a notable FID reduction of 2.17.
Token Pruning for Caching Better: 9$\times$ Acceleration on Stable Diffusion for Free
Evelyn Zhang*, Bang Xiao*, Jiayi Tang, Qianli Ma, Chang Zou, Xuefei Ning, Xuming Hu, Linfeng Zhang# (* equal contribution, # corresponding author)
arXiv preprint 2024
Based on token prune and layer cache technology, we present a new Stable Diffusion acceleration method named dynamics-aware token pruning (DaTo). In the COCO-30k, we observed a 7$\times$ acceleration coupled with a notable FID reduction of 2.17.